Im Zuge der digitalen Transformation, der vierten industriellen Revolution, dem Aufstieg von sozialen Medien und vielen weiteren teils disruptiven gesellschaftlichen Veränderungen sind Künstliche Intelligenzen (KI) in aller Munde. Die großen Tech-Riesen arbeiten mit diesen Künstlichen Intelligenzen und haben mit ihnen Geschäftsmodelle aufgebaut. Kleine- und mittelständische Unternehmen ziehen nach und versuchen ihre Datenschätze zu bergen, Prozesse zu optimieren und höhere Gewinne zu erzielen.
Bewusst wurde hier der Plural „Künstliche Intelligenzen“ verwendet, da diese jeweils als Software verstanden werden. Somit kann es beispielsweise mehrere Software-Anwendungen in einem Unternehmen geben, die die Kriterien einer KI erfüllen. Künstliche Intelligenz im Singular ist wiederum als ein theoretisches Konzept bzw. als Teilgebiet der Informatik zu verstehen.
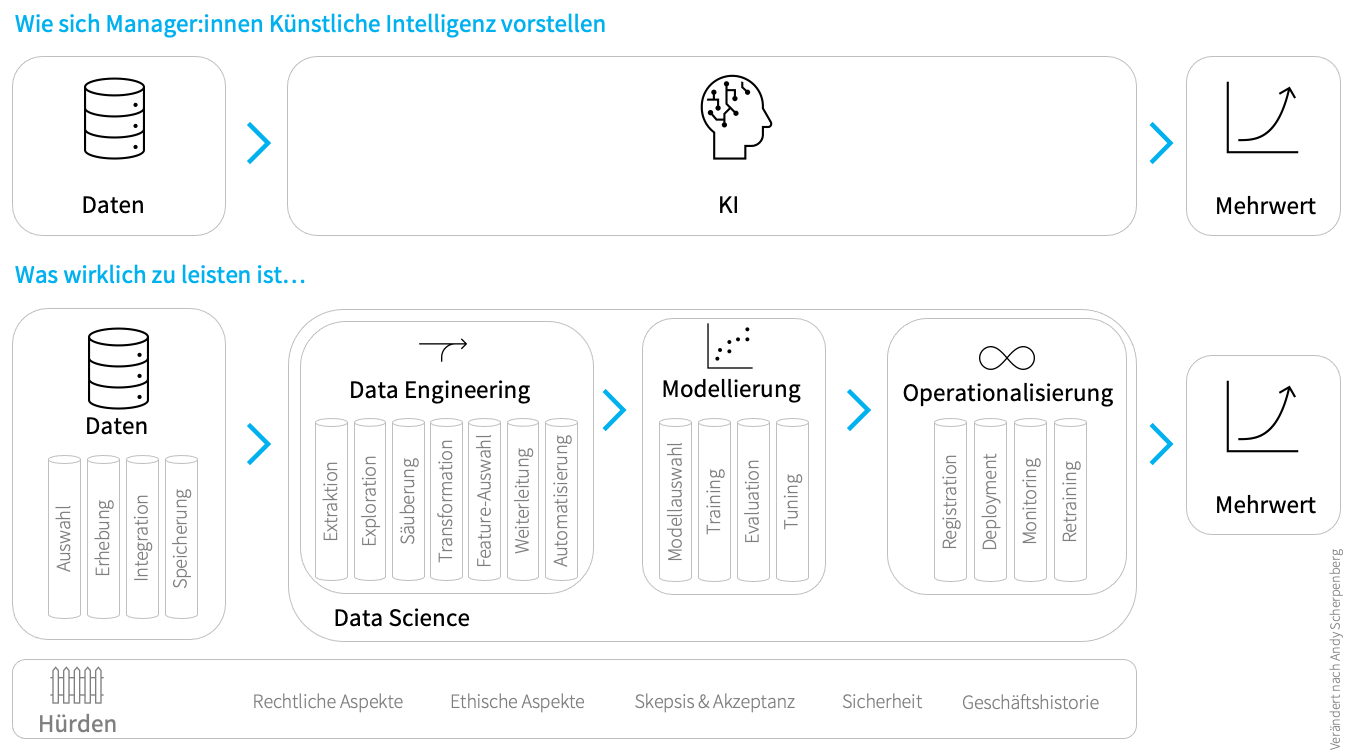
Oft genug wird in Unternehmen in den Management-Etagen und Geschäftsführungen vom Einsatz Künstlicher Intelligenz gesprochen, gar geschwärmt. Die Vorstellung, eine Technologie zu implementieren, die lernt das Unternehmen zu verstehen und Verbesserungsvorschläge macht, die beispielsweise den Umsatz steigern und dabei kein Gehalt verlangt oder Krankheitstage hat ist durchaus verlockend. Einzig: das können Künstliche Intelligenzen gar nicht leisten, auch wenn der Grundgedanke von Artifical Intelligence sicher in die Richtung ging, das menschliche Gehirn nachzuahmen und dieses Potential zu nutzen.
Data Scientists, die Künstliche Intelligenzen programmieren, benutzen diesen Begriff hingegen eher selten. Hier ist viel häufiger die Rede von Modellen, Algorithmen, Automatisierung oder schlichtweg Software. Auch wenn das, an dem sie arbeiten, vom Management als KI-Projekt deklariert wurde, ist das Verständnis der Data Scientists ein differenzierteres. Meist arbeiten sie nämlich an sogenannten schwachen KIs, also an Software die insbesondere mit maschinellem Lernen versucht, ein stark abgegrenztes und vereinfachtes Problem zu verstehen und dieses auf andere Probleme zur Lösung zur projizieren [1]. Hierzu werden statistische Methoden und Maschinelles Lernen genutzt. Von einer Intelligenz ist man hier weit entfernt, da sich das Verhalten nur bedingt auf andere Kontexte anwenden lässt.
Bei einer starken KI sprechen wir andererseits von einem Verhalten, dass einem Menschen ebenbürtig ist. In vielen Fällen sind dies humanoide Roboter. Doch auch hier ist bisweilen zu konstatieren, dass zwar ein biologisches Verhalten nachgeahmt werden kann, der Transfer von Erlerntem und die damit verbundene Entwicklung von einer tiefgehenden Intelligenz bislang aber kaum realisiert wurde. Darüber hinaus ist gar die Freiheit zu eigenständigen und unabhängigen Entscheidungen, wie sie als Dystopie in Filmen wie Terminator gezeichnet wird, in weiter Ferne.
Neben der durch Filme überzeichneten Intelligenz von Künstlichen Intelligenzen kann die schiere Übersetzung aus dem Englischen ein trügerisches Bild in den Köpfen erzeugen.
Bei intelligence haben wir neben der genannten Intelligenz auch Übersetzungen wie Geheimdienst, Spionage, aber auch Einsicht und Information. Wenn wir die letzteren Begriffe aufgreifen, kommt man viel näher an das, was wir als schwache KI bezeichnen. Mit klassischen statistischen Methoden, Data Science und maschinellem Lernen wird versucht, Information zu erlangen, die es bislang nicht gibt, beispielsweise über zukünftige Umsatzzahlen oder Muster in sehr großen Datensätzen.
In vergleichbaren Fällen würden wir auch nicht auf die Idee kommen, Business Intelligence mit Geschäftsintelligenz zu übersetzen. Dies ist schlicht die Information über das Geschäft, also beispielsweise Geschäftszahlen, die für Reportings benutzt werden. Anhand dieser Information treffen Menschen dann meist Entscheidungen. Auch die CIA, die Central Intelligence Agency ist keine Intelligenzagentur, sondern kümmert sich um die Beschaffung von Information auf Basis davon, dass Menschen Situationen bewerten und ihre Entscheidungen vornehmen.
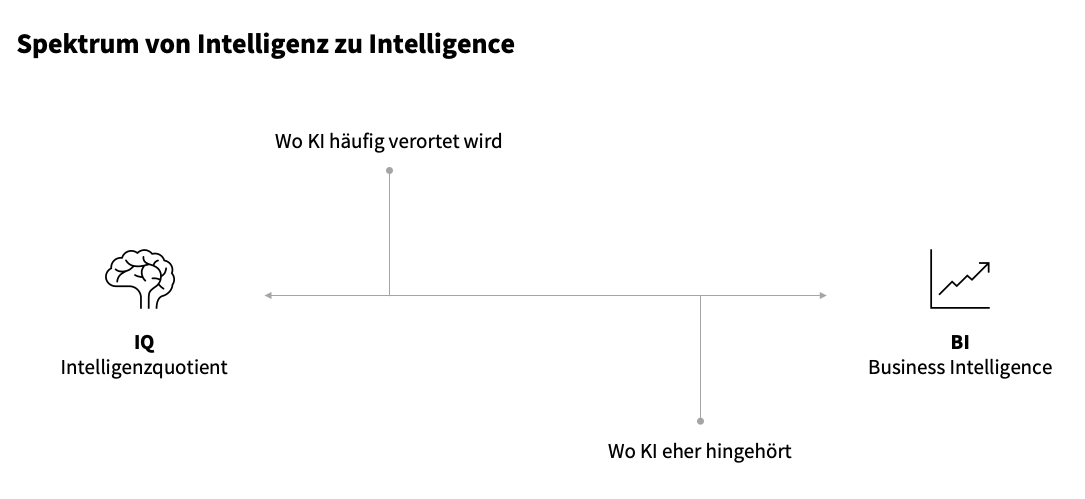
Im Gespräch mit Muttersprachlern, die technisch versiert sind und somit die vollumfängliche Tragweite der Thematik verstehen, haben wir eruiert, dass AI im englischsprachigen Raum auf einem Spektrum eher in der Nähe von Business Intelligence (BI) verortet wird (siehe Abbildung 2, rechts). KI wird im deutschsprachigen Raum wiederum eher in die Nähe von Intelligenz (links) gebracht, was der Technologie daher eher die Konnotation der Intelligenz mitgibt.
Wenn wir Artificial Intelligence als generierte Information verstehen, wäre klarer, was schwache KI in den meisten Fällen leistet: zusätzliche Einsichten und bislang nicht vorhandene Information zu einem Sachverhalt. Dabei soll eins nicht außer Acht gelassen werden: Selbst mit einer schwachen KI können wir intelligente Lösungen bauen, die uns den Alltag erleichtern oder uns Erkenntnisse bringen, die wir andernfalls nicht hätten.
Auch die starke KI kann dazu beitragen, unsere Welt lebenswerter, präziser und komfortabler zu machen. Viele Anwendungen in der Robotik, Medizin und dem autonomen Fahren wäre ohne KI nicht denkbar und ganz gewiss werden diese die nächsten Jahre maßgeblich prägen. Doch auf absehbare Zeit wird diese Technologie keine dem Menschen ebenbürtige Intelligenz oder gar Superintelligenz [4] hervorbringen.
So sprechen Data Scientists in den wenigsten Fällen von KI. Das Vorgehen der Analyse von Daten mit gewissen Unsicherheiten hin zu bislang fehlender Information, bezeichnen wir als Data Science. Der Rest ist Science Fiction.
Ressourcen
[1] Nils J. Nilsson: The Quest for Artificial Intelligence. A History of Ideas and Achievements. Cambridge University Press, New York, 2009.
[2] John Brockman: Possible Minds: Twenty-Five Ways of Looking at AI. Penguin Press, 2019.
[3] Hans Klumbies: Geschäftsanaytik. Datengrundlagen für Entscheidungen schaffen. 4. Juli 2012, abgerufen am 11. April 2022
[4] I. J. Good: Speculations Concerning the First Ultraintelligent Machine, 1965.